Последние новости науки
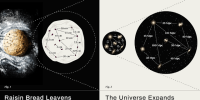
Wednesday, 24 April,


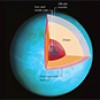
Saturday, 20 April,


Wednesday, 24 April,

Sunday, 21 April,




Наука в блогах

Всего 2 / shilovpope.livejournal.com
У меня наконец-то получилось полноценно понырять с нерестящимися нереисами! Это которые сейчас называются Alitta virens. Всего два-три дня в году тысячи / сотни тысяч...

Секреты успеха от сооснователя генетической лаборатории Дарьи Поповой / greenword.ru
Сегодня у нас в гостях очень интересная, талантливая и умная дама — Дарья Попова, специалист по ДНК, сооснователь генетический лаборатории «Медикал...

Перевернуть игру: зачем критикуют рациональность / scinquisitor.livejournal.com
Подсмотрел у Вадима Савицкого («Когнитивный Надзор») в недавнем видео интересную мысль, которую перескажу своими словами и немного расширю. Мне кажется, что...

Яркий 1812-й / m61.livejournal.com
Интересный доклад я услышал сегодня на семинаре. Как известно, в центре нашей Галактики находится сверхмассивная черная дыра (ну, по космическим меркам она не...
ШБО, III тур / prokhozhyj.livejournal.com
Вотпрямсейчас. Раскочегарился и пыхтит III тур LXXIII ШБО. Это когда гг. члены Жюри минут по сорок мучают всякими вопросами имевшего неосторожность...

Девятый ChillOutPlanet Festival в Пушкинских горах / greenword.ru
В июле 2023 года в Пушкинских горах прошёл девятый ежегодный мультижанровый музыкальный ChillOutPlanet Festival. Программа шестидневного фестиваля включала в себя живую и...