

Вокруг первой демонстрации квантового превосходства вычислителем Sycamore компании Google было много споров и сомнений. Одно из них касалось оценки времени работы классического компьютера. Китайские ученые разработали и реализовали алгоритм, который заставляет пересмотреть результаты Google о квантовом ускорении. Им потребовалось 60 графических процессоров и пять дней для решения задачи, на которую, по оценкам Google, суперкомпьютер должен был потратить 10 тысяч лет. Препринт работы опубликован на arXiv.org.В октябре 2019 коллектив ученых Google заявил, что им удалось экспериментально продемонстрировать квантовое превосходство. Они использовали квантовый 53-кубитный вычислитель Sycamore на сверхпроводниках для того, чтобы решить задачу генерации случайной строки. По утверждениям исследователей, решение этой задачи должно занять около 10 тысяч лет у самого мощного суперкомпьютера Sammit, в то время как Sycamore справился с ней за 200 секунд.Понятно, что выбор задачи не был случайным - это одна из удобных задач для демонстрации мощности квантовых вычислителей. Тем не менее, даже при таких условиях, исследователи из IBM подвергли критике расчеты времени выполнения задачи на классическом компьютере. Буквально через месяц после новости об эксперименте Google, они опубликовали препринт статьи, в котором утверждали, что суперкомпьютеру может потребоваться несколько дней для решения задачи при правильном использовании памяти. Дело в том, что оценки времени ученых Google строились на том, что оперативной памяти суперкомпьютера окажется недостаточно и придется использовать алгоритмы, которые экономят память в ущерб времени работы. В IBM ученые предложили другой подход: использовать не только оперативную память, но и хранить нужную информацию на жестких дисках.Несмотря на активные споры, ни одна из компаний не проводила предложенные вычисления в полном объеме - всех их предположения были только теоретическими. Решить задачу и разрешить спор удалось группе ученых из Института теоретической физики Китайской академии наук под руководством Пань Чжаня (Pan Zhang). Они предложили новый комбинированный алгоритм, с помощью которого смогли решить задачу генерации случайной строки на маленьком вычислительном кластере из 60 графических процессоров. Весь расчет занял у исследователей 5 дней, а итоговая точность значительно превысила ту, что получил квантовый вычислитель Google.

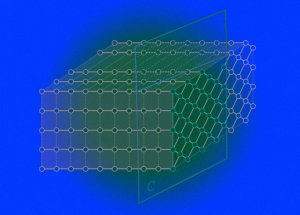
Разделение трехмерной тензорной сети на подгруппыFeng Pan and Pan Zhang / arXiv.org, 2021Квантовая схема Sycamore, как и любая другая, имеет два важных с точки зрения сложности задачи параметра - размерность или число кубитов и глубина или число слоев гейтов (операций над кубитами). Чем больше кубитов или чем больше операций над ними нужно осуществить, тем сложнее будет смоделировать такую цепь на классическом компьютере. Существует два основных метода их моделирования.Первый (метод Шредингера) хранит в памяти полный вектор состояния и использует знание вероятности каждой строки для генерации выборки строк. Поэтому вычислительная сложность такого метода линейно растет с увеличением глубины цепи. Эта зависимость важна для моделирования, потому что глубина цепи вычислителя Sycamore была равна 20. С другой стороны, зависимость сложности такого метода от числа кубитов оказывается экспоненциальной, поэтому смоделировать систему с большим число кубитов оказывается затруднительно (в Sycamore их было 53).Второй метод использует тензорные сети и отлично работает для неглубоких цепей с большим числом кубитов благодаря перегруппировке входных данных. Авторы решили объединить два метода для того, чтобы новый алгоритм мог моделировать цепи и с большим числом кубитов и с большой глубиной. Они использовали тензорную сеть, для того, чтобы разделить все кубиты на подгруппы, каждую из которых отдельно моделировали на разных графических процессорах. В результате число кубитов в каждой подгруппе становится достаточным, чтобы применить метод Шредингера и решить задачу за реальное время (значительно меньше 10 тысяч лет). Ученым потребовалось 60 графических процессоров NVIDIA V100 GPU с 32 гигабайтами памяти и пять дней для генерации двух миллионов строк. Кроме того, качество распределения этих строк значительно превосходит соответствующий результат Sycamore.После генерации большого числа случайных строк какие-то из них встречаются чаще, а какие-то реже. Поэтому можно говорить о вероятности генерации определенной строки. Зависимость вероятности от строки может иметь определенный вид. Результат задачи, которую решали авторы, в идеальном случае должен иметь распределение Портера-Томаса. Чем ближе реальное распределение к распределению Портера-Томаса, тем точнее и лучше оказывается решена задача. Обычно для оценки близости распределений используют величину их схожести (fidelity). Если она равна единице, то распределения полностью совпадают. В эксперименте Google схожесть итоговых распределений составила всего 0,002, а авторам новой работы удалось получить значение в 0,739.Несмотря на то, что ученые сосредоточились на моделировании Sycamore, их алгоритм и подход в целом можно использовать для моделирования существующих и будущих квантовых систем. Они отмечают, что в отличие от квантового вычислителя Google, их алгоритм не масштабируем на большие глубины и числа кубитов одновременно.Помимо задачи генерации случайной строки, физики активно исследуют и создают квантовые вычислители для решения задачи бозонного сэмплинга. Фотонный процессор группы китайских ученых уже справился с этой задачей, а другая команда предложила новый способ для увеличения размерности задачи. Интересно, сможет ли разработанный классический алгоритм справиться с задачей бозонного сэмплинга быстрее, чем все существующие.Оксана Борзенкова(https://nplus1.ru/news/20...)







Комментарии (0)