



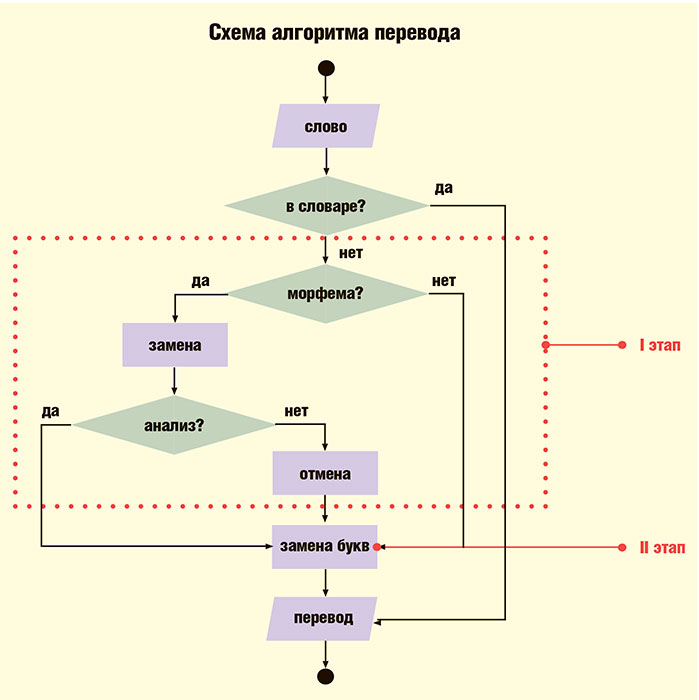
 – В первом случае в результате применения правила перевода, мы получим верный результат – тростью. В ситуации со вторым словом получится несуществующая лексема – эволюцью. Наш алгоритм, проанализировав результат работы морфологического анализатора, увидит это и отменит примененное правило, после чего на втором этапе перевода произойдет замена устаревшей «i» на современную «и» и мы получим верный перевод – эволюцию, – рассказывает магистрант механико-математического факультета НГУ, инженер-программист ФИЦ ИВТ Елизавета Тагирова. – Конечно, неизбежно останутся такие случаи, в которых эксперт должен будет решать, правильно сделан перевод или нет, – объясняет старший научный сотрудник ФИЦ ИВТ, кандидат филологических наук Ольга Кожемякина. – Например, в слове «концемъ» («концом» в современном виде) алгоритм видит окончание и не подозревает, что это какая-то устаревшая морфема. Он просто убирает «ъ» на конце, но этого недостаточно. Этот пример не попадает в какую-либо категорию написания морфем, участники проекта не нашли такого ни в одном справочнике. Предположительно написание объясняется тем, что когда-то «ц» обозначала мягкий звук. Чем старее текст, тем больше можно найти подобных примеров, требующих вмешательства эксперта в силу того, что не все правила кодифицированы: в печатном слове традиции и инерция намного сильнее, чем в живой речи. Мы допускаем, что на тот момент люди уже говорили «концом», а писали все еще в соответствии с традицией печатного слова. В культуре того времени печатные издания выступали эталоном. Так что в данном случае компьютер заменяет не ученого, а, скорее, корректора. Пока программа еще не способна анализировать случаи, которых нет в справочниках. Но в случае спроса – например, со стороны библиотек с большим объемом дореволюционной литературы – ее возможно доработать. Подобные проекты стимулируют междисциплинарное сотрудничество, традиционно характерное для институтов Сибирского отделения РАН. – В чем главные достоинства данного проекта РНФ? Прежде всего он позволил интегрироваться в одну команду специалистам по информационным технологиям и филологам – профессиональному пушкинисту Ольге Юрьевне Кожемякиной, заведующей кафедрой фундаментальной и прикладной лингвистики Гуманитарного института Новосибирского государст-венного университета, доктору филологических наук Марии Кирилловне Тимофеевой, – подчеркивает В.Барахнин. – Я занимаюсь компьютерной лингвистикой с начала 2000-х годов, сотрудничал с коллегами из Казахстана, помогал им развивать методы обработки информации на казахском языке. Сейчас вместе с магистрантами НГУ из Узбекистана решаю аналогичную задачу для узбекского языка. Но наш проект помог мне осуществить давнюю мечту – реализовать в исследованиях интерес к русской классической поэзии, зародившийся еще в школе. В нашей области исследований не нужны ни специальное оборудование (прекрасные компьютеры есть в федеральном исследовательском центре), ни расходные материалы, поэтому второе преимущество проекта я вижу в том, что он дает возможность привлечь к работе достаточное количество аспирантов, причем самых разных специальностей: математиков, программистов, лингвистов. В нашей команде много недавних выпускников НГУ, и благодаря поддержке РНФ они могут сосредоточиться на исследованиях и подготовке к защите кандидатской диссертации, не думая ежедневно о хлебе насущном. Дополнительным бонусом становятся командировки и участие в конференциях. Фактически наша команда работает следующим образом: генерируют идеи более опытные участники – М.К.Тимофеева, О.Ю.Кожемякина, ваш покорный слуга – а их практической компьютерной реализацией занимается молодежь – аспиранты и магистранты. Проект Российского научного фонда по многоуровневому исследованию стихотворных текстов рассчитан на 2019-2021 годы. За 2019-й кроме вышеупомянутого автоматического переводчика дореволюционных текстов с учетом морфологии слов были разработаны алгоритм автоматического определения стопности, определяющий, в частности, рифму в стихотворениях А.С.Пушкина с точностью в 95%, а также реализованный в виде веб-приложения алгоритм построения конкордансов. Надо сказать, это – тот случай, когда количество переходит в качество: радикальное увеличение объема анализируемого корпуса русских поэтических текстов должно вывести филологические исследования на новый качественный уровень. Первыми кандидатами на «поверку гармонии алгеброй» выбраны Алексей Константинович Толстой и Иннокентий Федорович Анненский. Именно их творчество подвергнется комплексному анализу с использованием разработанных ФИЦ ИВТ алгоритмов.Ольга КОЛЕСОВАThe post Алгоритмы гармонии. На помощь лингвистам пришли программисты appeared first on Поиск - новости науки и техники.
– В первом случае в результате применения правила перевода, мы получим верный результат – тростью. В ситуации со вторым словом получится несуществующая лексема – эволюцью. Наш алгоритм, проанализировав результат работы морфологического анализатора, увидит это и отменит примененное правило, после чего на втором этапе перевода произойдет замена устаревшей «i» на современную «и» и мы получим верный перевод – эволюцию, – рассказывает магистрант механико-математического факультета НГУ, инженер-программист ФИЦ ИВТ Елизавета Тагирова. – Конечно, неизбежно останутся такие случаи, в которых эксперт должен будет решать, правильно сделан перевод или нет, – объясняет старший научный сотрудник ФИЦ ИВТ, кандидат филологических наук Ольга Кожемякина. – Например, в слове «концемъ» («концом» в современном виде) алгоритм видит окончание и не подозревает, что это какая-то устаревшая морфема. Он просто убирает «ъ» на конце, но этого недостаточно. Этот пример не попадает в какую-либо категорию написания морфем, участники проекта не нашли такого ни в одном справочнике. Предположительно написание объясняется тем, что когда-то «ц» обозначала мягкий звук. Чем старее текст, тем больше можно найти подобных примеров, требующих вмешательства эксперта в силу того, что не все правила кодифицированы: в печатном слове традиции и инерция намного сильнее, чем в живой речи. Мы допускаем, что на тот момент люди уже говорили «концом», а писали все еще в соответствии с традицией печатного слова. В культуре того времени печатные издания выступали эталоном. Так что в данном случае компьютер заменяет не ученого, а, скорее, корректора. Пока программа еще не способна анализировать случаи, которых нет в справочниках. Но в случае спроса – например, со стороны библиотек с большим объемом дореволюционной литературы – ее возможно доработать. Подобные проекты стимулируют междисциплинарное сотрудничество, традиционно характерное для институтов Сибирского отделения РАН. – В чем главные достоинства данного проекта РНФ? Прежде всего он позволил интегрироваться в одну команду специалистам по информационным технологиям и филологам – профессиональному пушкинисту Ольге Юрьевне Кожемякиной, заведующей кафедрой фундаментальной и прикладной лингвистики Гуманитарного института Новосибирского государст-венного университета, доктору филологических наук Марии Кирилловне Тимофеевой, – подчеркивает В.Барахнин. – Я занимаюсь компьютерной лингвистикой с начала 2000-х годов, сотрудничал с коллегами из Казахстана, помогал им развивать методы обработки информации на казахском языке. Сейчас вместе с магистрантами НГУ из Узбекистана решаю аналогичную задачу для узбекского языка. Но наш проект помог мне осуществить давнюю мечту – реализовать в исследованиях интерес к русской классической поэзии, зародившийся еще в школе. В нашей области исследований не нужны ни специальное оборудование (прекрасные компьютеры есть в федеральном исследовательском центре), ни расходные материалы, поэтому второе преимущество проекта я вижу в том, что он дает возможность привлечь к работе достаточное количество аспирантов, причем самых разных специальностей: математиков, программистов, лингвистов. В нашей команде много недавних выпускников НГУ, и благодаря поддержке РНФ они могут сосредоточиться на исследованиях и подготовке к защите кандидатской диссертации, не думая ежедневно о хлебе насущном. Дополнительным бонусом становятся командировки и участие в конференциях. Фактически наша команда работает следующим образом: генерируют идеи более опытные участники – М.К.Тимофеева, О.Ю.Кожемякина, ваш покорный слуга – а их практической компьютерной реализацией занимается молодежь – аспиранты и магистранты. Проект Российского научного фонда по многоуровневому исследованию стихотворных текстов рассчитан на 2019-2021 годы. За 2019-й кроме вышеупомянутого автоматического переводчика дореволюционных текстов с учетом морфологии слов были разработаны алгоритм автоматического определения стопности, определяющий, в частности, рифму в стихотворениях А.С.Пушкина с точностью в 95%, а также реализованный в виде веб-приложения алгоритм построения конкордансов. Надо сказать, это – тот случай, когда количество переходит в качество: радикальное увеличение объема анализируемого корпуса русских поэтических текстов должно вывести филологические исследования на новый качественный уровень. Первыми кандидатами на «поверку гармонии алгеброй» выбраны Алексей Константинович Толстой и Иннокентий Федорович Анненский. Именно их творчество подвергнется комплексному анализу с использованием разработанных ФИЦ ИВТ алгоритмов.Ольга КОЛЕСОВАThe post Алгоритмы гармонии. На помощь лингвистам пришли программисты appeared first on Поиск - новости науки и техники.
Другие новости от poisknews.ru

Реклама на проекте
Алгоритмы гармонии. На помощь лингвистам пришли программисты
Saturday, 27 June, 20:06,
poisknews.ru
26.06.2020Насколько устойчивы традиции русской поэзии? Влияет ли размер стихотворения на содержание? Еще в 1960-х годах американский филолог-славист Кирилл Тарановский высказал предположение о связи формальных характеристик стиха с его жанром. Например, лермонтовское «Выхожу один я на дорогу…» написано пятистопным хореем. Те же размер и строфика характерны для «Вот бреду я вдоль большой дороги…» Федора Тютчева, «Вот я выхожу, открытый взорам…» Александра Блока, «Гул затих. Я вышел на подмостки» Бориса Пастернака. Эти стихотворения объединены общим жанром – раздумья идущего героя о жизненном выборе. К.Тарановский предложил методику определения семантики того или иного стихотворного размера, заключающуюся в исследовании не единичных употреблений, а традиции его жанрового и тематического использования, что предполагает анализ целых корпусов русских поэтических текстов. Естественно, такой подход требует автоматизации. И полвека спустя на помощь лингвистам пришли программисты – в Институте вычислительных технологий СО РАН, недавно ставшем Федеральным исследовательским центром, реализуется поддержанный Российским научным фондом проект «Разработка и реализация информационной системы многоуровневого исследования стихотворных текстов». – Наша задача – освободить исследователей от рутинной работы, – рассказывает руководитель проекта доктор технических наук Владимир Барахнин. – Впервые будут предложены алгоритмы исследования взаимозависимости фонометрического и лексико-тематического уровней стихотворных текстов. Проще говоря, программа поможет выявить и провести количественный анализ связи смысловых ассоциаций со стихотворными размерами. Причем может быть исследован такой массив текстов, обработать который филологу-одиночке попросту не под силу. Автоматизация позволит расширить круг исследуемых авторов. Чтобы полностью автоматизировать анализ русской классической поэзии XIX-XX веков, необходимо составить метрические справочники к корпусу стихов того или иного поэта, содержащие сведения о системах стихосложения, размерах, каталектике (ритмических окончаниях стихов), строфике, метрической композиции стихотворений. Кроме того, понадобятся словари рифм, конкордансов (алфавитных перечней всех слов текста с указанием контекстов их употребления) и статистические словари слов и словосочетаний, употребляемых как отдельными поэтами, так и представителями определенных литературных направлений. Эти справочники и словари важны и для непосредственного изучения художественной техники поэта, и в качестве основы для проведения количественного анализа связей содержания текстов со стихотворными размерами. Пытаясь перелопатить этот поэтический пласт, специалисты ИВТ неожиданно помогли сотрудникам библиотек – в ходе работы над проектом был создан алгоритм для перевода старой орфографии в современную. При оцифровке дореволюционного издания можно будет преобразовать текст в привычный для сегодняшнего читателя вид. Работа над программой осложнялась тем, что до середины XX века в русском языке не было официально утвержденной орфографии. – До революции появлялись орфографические справочники, на их основании писались гимназические грамматики, но нормы не были кодифицированы. Декрет Совета народных комиссаров от 10 октября 1918 года «О введении новой орфографии» был весьма краток и описывал то, что требует изменения, причем далеко не полностью. Например, вышло так, что ижица (Ѵ) вообще не была упомянута, – поясняет В.Барахнин. – Для разработки программы за основу был взят «Справочник по старой орфографии русского языка» П.И.Давыдова, изучившего и проанализировавшего значительное количество источников и литературы, в том числе учебники, словари и справочники, изданные в старой орфографии до 1917 года. В этом справочнике изложен ряд изменений, которые можно разделить на две большие категории: правописание морфем (приставок, падежных окончаний) и употребление отдельных букв. На основе перечисленных в справочнике норм дореволюционного правописания был разработан переводчик. Скажем, нужно выяснить современное написание слова «тростiю». Казалось бы, все просто: для этой группы окончание должно быть заменено на «-ью» – тростью. Однако такое же окончание может иметь и слово «эволюцiю».– В первом случае в результате применения правила перевода, мы получим верный результат – тростью. В ситуации со вторым словом получится несуществующая лексема – эволюцью. Наш алгоритм, проанализировав результат работы морфологического анализатора, увидит это и отменит примененное правило, после чего на втором этапе перевода произойдет замена устаревшей «i» на современную «и» и мы получим верный перевод – эволюцию, – рассказывает магистрант механико-математического факультета НГУ, инженер-программист ФИЦ ИВТ Елизавета Тагирова. – Конечно, неизбежно останутся такие случаи, в которых эксперт должен будет решать, правильно сделан перевод или нет, – объясняет старший научный сотрудник ФИЦ ИВТ, кандидат филологических наук Ольга Кожемякина. – Например, в слове «концемъ» («концом» в современном виде) алгоритм видит окончание и не подозревает, что это какая-то устаревшая морфема. Он просто убирает «ъ» на конце, но этого недостаточно. Этот пример не попадает в какую-либо категорию написания морфем, участники проекта не нашли такого ни в одном справочнике. Предположительно написание объясняется тем, что когда-то «ц» обозначала мягкий звук. Чем старее текст, тем больше можно найти подобных примеров, требующих вмешательства эксперта в силу того, что не все правила кодифицированы: в печатном слове традиции и инерция намного сильнее, чем в живой речи. Мы допускаем, что на тот момент люди уже говорили «концом», а писали все еще в соответствии с традицией печатного слова. В культуре того времени печатные издания выступали эталоном. Так что в данном случае компьютер заменяет не ученого, а, скорее, корректора. Пока программа еще не способна анализировать случаи, которых нет в справочниках. Но в случае спроса – например, со стороны библиотек с большим объемом дореволюционной литературы – ее возможно доработать. Подобные проекты стимулируют междисциплинарное сотрудничество, традиционно характерное для институтов Сибирского отделения РАН. – В чем главные достоинства данного проекта РНФ? Прежде всего он позволил интегрироваться в одну команду специалистам по информационным технологиям и филологам – профессиональному пушкинисту Ольге Юрьевне Кожемякиной, заведующей кафедрой фундаментальной и прикладной лингвистики Гуманитарного института Новосибирского государст-венного университета, доктору филологических наук Марии Кирилловне Тимофеевой, – подчеркивает В.Барахнин. – Я занимаюсь компьютерной лингвистикой с начала 2000-х годов, сотрудничал с коллегами из Казахстана, помогал им развивать методы обработки информации на казахском языке. Сейчас вместе с магистрантами НГУ из Узбекистана решаю аналогичную задачу для узбекского языка. Но наш проект помог мне осуществить давнюю мечту – реализовать в исследованиях интерес к русской классической поэзии, зародившийся еще в школе. В нашей области исследований не нужны ни специальное оборудование (прекрасные компьютеры есть в федеральном исследовательском центре), ни расходные материалы, поэтому второе преимущество проекта я вижу в том, что он дает возможность привлечь к работе достаточное количество аспирантов, причем самых разных специальностей: математиков, программистов, лингвистов. В нашей команде много недавних выпускников НГУ, и благодаря поддержке РНФ они могут сосредоточиться на исследованиях и подготовке к защите кандидатской диссертации, не думая ежедневно о хлебе насущном. Дополнительным бонусом становятся командировки и участие в конференциях. Фактически наша команда работает следующим образом: генерируют идеи более опытные участники – М.К.Тимофеева, О.Ю.Кожемякина, ваш покорный слуга – а их практической компьютерной реализацией занимается молодежь – аспиранты и магистранты. Проект Российского научного фонда по многоуровневому исследованию стихотворных текстов рассчитан на 2019-2021 годы. За 2019-й кроме вышеупомянутого автоматического переводчика дореволюционных текстов с учетом морфологии слов были разработаны алгоритм автоматического определения стопности, определяющий, в частности, рифму в стихотворениях А.С.Пушкина с точностью в 95%, а также реализованный в виде веб-приложения алгоритм построения конкордансов. Надо сказать, это – тот случай, когда количество переходит в качество: радикальное увеличение объема анализируемого корпуса русских поэтических текстов должно вывести филологические исследования на новый качественный уровень. Первыми кандидатами на «поверку гармонии алгеброй» выбраны Алексей Константинович Толстой и Иннокентий Федорович Анненский. Именно их творчество подвергнется комплексному анализу с использованием разработанных ФИЦ ИВТ алгоритмов.Ольга КОЛЕСОВАThe post Алгоритмы гармонии. На помощь лингвистам пришли программисты appeared first on Поиск - новости науки и техники.
– В первом случае в результате применения правила перевода, мы получим верный результат – тростью. В ситуации со вторым словом получится несуществующая лексема – эволюцью. Наш алгоритм, проанализировав результат работы морфологического анализатора, увидит это и отменит примененное правило, после чего на втором этапе перевода произойдет замена устаревшей «i» на современную «и» и мы получим верный перевод – эволюцию, – рассказывает магистрант механико-математического факультета НГУ, инженер-программист ФИЦ ИВТ Елизавета Тагирова. – Конечно, неизбежно останутся такие случаи, в которых эксперт должен будет решать, правильно сделан перевод или нет, – объясняет старший научный сотрудник ФИЦ ИВТ, кандидат филологических наук Ольга Кожемякина. – Например, в слове «концемъ» («концом» в современном виде) алгоритм видит окончание и не подозревает, что это какая-то устаревшая морфема. Он просто убирает «ъ» на конце, но этого недостаточно. Этот пример не попадает в какую-либо категорию написания морфем, участники проекта не нашли такого ни в одном справочнике. Предположительно написание объясняется тем, что когда-то «ц» обозначала мягкий звук. Чем старее текст, тем больше можно найти подобных примеров, требующих вмешательства эксперта в силу того, что не все правила кодифицированы: в печатном слове традиции и инерция намного сильнее, чем в живой речи. Мы допускаем, что на тот момент люди уже говорили «концом», а писали все еще в соответствии с традицией печатного слова. В культуре того времени печатные издания выступали эталоном. Так что в данном случае компьютер заменяет не ученого, а, скорее, корректора. Пока программа еще не способна анализировать случаи, которых нет в справочниках. Но в случае спроса – например, со стороны библиотек с большим объемом дореволюционной литературы – ее возможно доработать. Подобные проекты стимулируют междисциплинарное сотрудничество, традиционно характерное для институтов Сибирского отделения РАН. – В чем главные достоинства данного проекта РНФ? Прежде всего он позволил интегрироваться в одну команду специалистам по информационным технологиям и филологам – профессиональному пушкинисту Ольге Юрьевне Кожемякиной, заведующей кафедрой фундаментальной и прикладной лингвистики Гуманитарного института Новосибирского государст-венного университета, доктору филологических наук Марии Кирилловне Тимофеевой, – подчеркивает В.Барахнин. – Я занимаюсь компьютерной лингвистикой с начала 2000-х годов, сотрудничал с коллегами из Казахстана, помогал им развивать методы обработки информации на казахском языке. Сейчас вместе с магистрантами НГУ из Узбекистана решаю аналогичную задачу для узбекского языка. Но наш проект помог мне осуществить давнюю мечту – реализовать в исследованиях интерес к русской классической поэзии, зародившийся еще в школе. В нашей области исследований не нужны ни специальное оборудование (прекрасные компьютеры есть в федеральном исследовательском центре), ни расходные материалы, поэтому второе преимущество проекта я вижу в том, что он дает возможность привлечь к работе достаточное количество аспирантов, причем самых разных специальностей: математиков, программистов, лингвистов. В нашей команде много недавних выпускников НГУ, и благодаря поддержке РНФ они могут сосредоточиться на исследованиях и подготовке к защите кандидатской диссертации, не думая ежедневно о хлебе насущном. Дополнительным бонусом становятся командировки и участие в конференциях. Фактически наша команда работает следующим образом: генерируют идеи более опытные участники – М.К.Тимофеева, О.Ю.Кожемякина, ваш покорный слуга – а их практической компьютерной реализацией занимается молодежь – аспиранты и магистранты. Проект Российского научного фонда по многоуровневому исследованию стихотворных текстов рассчитан на 2019-2021 годы. За 2019-й кроме вышеупомянутого автоматического переводчика дореволюционных текстов с учетом морфологии слов были разработаны алгоритм автоматического определения стопности, определяющий, в частности, рифму в стихотворениях А.С.Пушкина с точностью в 95%, а также реализованный в виде веб-приложения алгоритм построения конкордансов. Надо сказать, это – тот случай, когда количество переходит в качество: радикальное увеличение объема анализируемого корпуса русских поэтических текстов должно вывести филологические исследования на новый качественный уровень. Первыми кандидатами на «поверку гармонии алгеброй» выбраны Алексей Константинович Толстой и Иннокентий Федорович Анненский. Именно их творчество подвергнется комплексному анализу с использованием разработанных ФИЦ ИВТ алгоритмов.Ольга КОЛЕСОВАThe post Алгоритмы гармонии. На помощь лингвистам пришли программисты appeared first on Поиск - новости науки и техники.

Комментарии (0)